

从命令地址到位智,再到要求Siri等私人助理为您完成任务,越来越多的产品和服务正在迁移到云中,并受到语音的控制。Hila Yonatan正在从用户体验的角度讨论这一新趋势,它对我们将要使用的下一个产品/功能有何看法?
From dictating addresses to Waze to asking personal assistants such as Siri to do tasks for you, more and more products and services are migrating to the cloud, and being controlled by voice. Hila Yonatan is discussing this new trend from a UX perspective, and what does it say about the next product/feature we’re going to work with?
当Apple首次推出Siri时,他们可能已经计划改变世界-但他们可能没有预料到我们对技术设备的看法会有所改变。的确,围绕Siri的大量宣传是苹果旗舰产品(如果您可以将Siri称为“产品”)这一事实的直接衍生,但是即使是苛刻的批评家也很难忽略新Siri的重要性。闪亮的私人助理,乔布斯将所有筹码都放在上面。有无数人上传了他们与Siri互动的视频。BuzzFeed列出了“最有趣的20个Siri反应”列表,甚至该主题的戏剧化版本在电影“她”中也得到了永久体现,由斯嘉丽·约翰逊(Scarlett Johansson)饰演Siri-not-Siri。

When Apple first launched Siri, they probably have planned on changing the world – but they might not have anticipated the extent of the shift in our perspective towards technological devices. It’s true, much of the hype surrounding Siri is a direct derivative of the fact that it’s an Apple flagship product (if you can call Siri “a product”), but even a harsh critic would have a tough time overlooking the importance of the new & shiny personal assistant, on which Jobs had all his chips on. Countless people had uploaded videos of them interacting with Siri. BuzzFeed lists of the “20 of the funniest Siri reactions” were published, and even a dramatized version of the topic was immortalized in the movie “Her”, starring Scarlett Johansson as Siri-not-Siri.
从那里,语音用户界面被推到舞台中央。这项技术使我们能够与家用电器对话,改变了我们眼前的世界呢?它将如何影响我们将来使用的产品?从专业的角度来看:它对即将发布的界面有什么看法,设计界面的人员将在多大程度上调整他们的思维方式?
From there, voice user interfaces were pushed to the center of the stage. What is it about this technology, which allows us to talk to our home appliances, that changes the world in front of our eyes? How does it affect the products we’ll use in the future? From a professional standpoint: what does it say about the upcoming interfaces, and to what extent the people who design them will have to adjust their way of thinking?

我们实际上如何使用这个东西?
How do we actually use this thing?
我们对自动化了解的越多,我们周围的设备就越智能-我们在各种产品中看到了更大范围的语音用户界面。当我第一次了解该功能以指示Waze或Google Maps上的“我要去”的位置,或在不键入键的情况下设置提醒时,我以为我们会在应用程序中看到越来越多的此类活动。
The more we learn about automation, and the devices around us get smarter – we see a larger array of voice user interfaces in various products. When I first learned about the feature to dictate where “I’m going to” on Waze or Google Maps, or set a reminder without typing keys, I assumed we’d see an increasing number of such activities in apps.

如果几年前我们谈论物联网(“物联网”,一个声称每个设备都是基于网络的实体的概念),那么今天我们看到它不再是科幻想法,而是事实。这种趋势已经在两架飞机相互帮助的情况下逐渐消失。
If we talked about IoT (the “Internet of Things”, a concept that claims that every device is a network-based entity) a few years back, nowadays we see that it’s no longer a sci-fi idea, but a factual reality. This trend had come to pass with the help of two planes that had grown one towards the other.
第一个 -事实是“一个万能的应用程序”。大多数电器都以一种方式来控制。它从通过打印机和智能电视机连接互联网的灯泡开始,直到通过单击专用应用程序中的大型透明按钮锁定前门的能力。
The first – the fact that there’s “an app for everything”. Most electric appliances, in one way or another, are being controlled with an app. It’s starting with internet-connected light bulbs, via printers and smart TV sets, up until the ability to lock your front door by clicking a large, clear button in a dedicated app.

第二个 -智能助手。几年前,这是科幻小说,但今天我们可以看到每个人都对此感兴趣。它从Siri开始,进入具有Alexa的Amazon Echo设备,谷歌也与助手一起加入了潮流(我想知道为什么他们决定不给自己的角色起一个人的名字),甚至微软也从Corani那里撤下了Cortana。电子游戏世界变成现实。
The second – smart assistants. A few years ago this was a science fiction scenario, but today we can see that everyone’s onboard on this. It had started with Siri, made its way to the Amazon Echo devices featuring Alexa, Google also joined the bandwagon with their Assistant (I wonder why they’ve decided not to give their persona a human name) and even Microsoft had pulled Cortana from the videogame world into reality.
所有这些都与您的帐户相关联,能够提醒您重要的会议或设置计时器来煮鸡蛋,但是这些应用程序具有的潜力不仅仅可以帮助用户做事或记住事情!
All of these are connected to your accounts, are able to remind you of an important meeting or set a timer for boiling an egg, but the potential that these applications have is much more than just helping a user do or remember stuff!

最近,我们已经看到这两个向量合并为一个乘积。因此,如果您可以聘请一位真正的私人助理,他可以从事许多活动(除了未定义的活动,例如“从地板上捡起”或“整理行李”),您会要求他们做什么?做,什么时候?
Recently, we’ve seen those two vectors merge into one product. So, if you could have hired a real personal assistants, who could do many of your activities (aside of non-defined activities, such as “pick up from the floor” or “pack a bag”), what would you ask them to do, and when?
从云端管理您的一天
Managing your day from the cloud
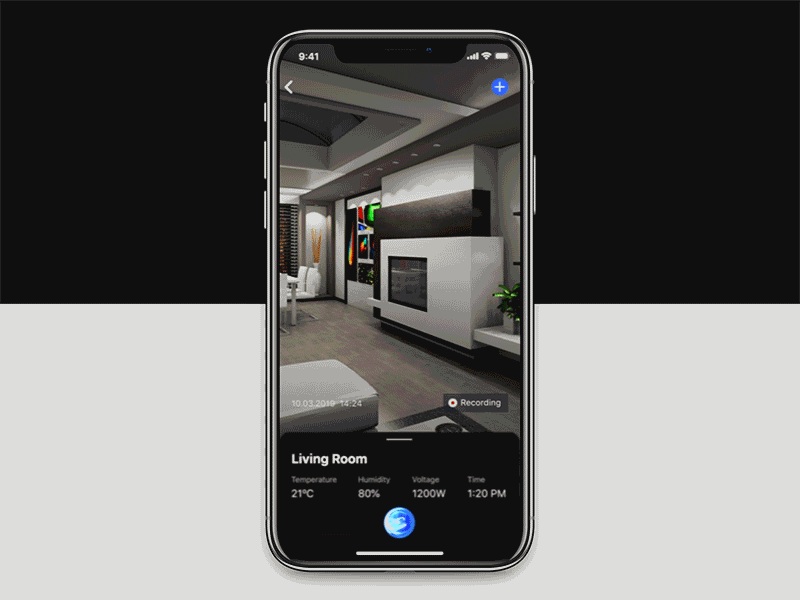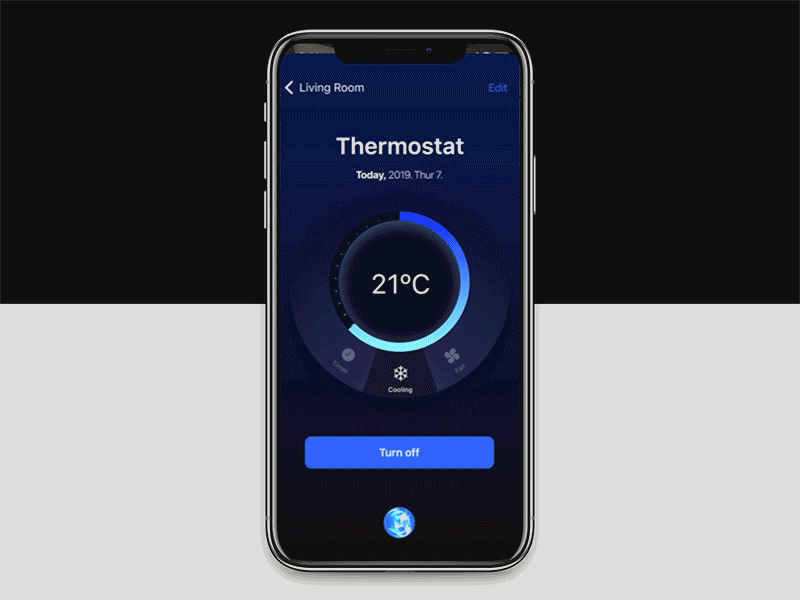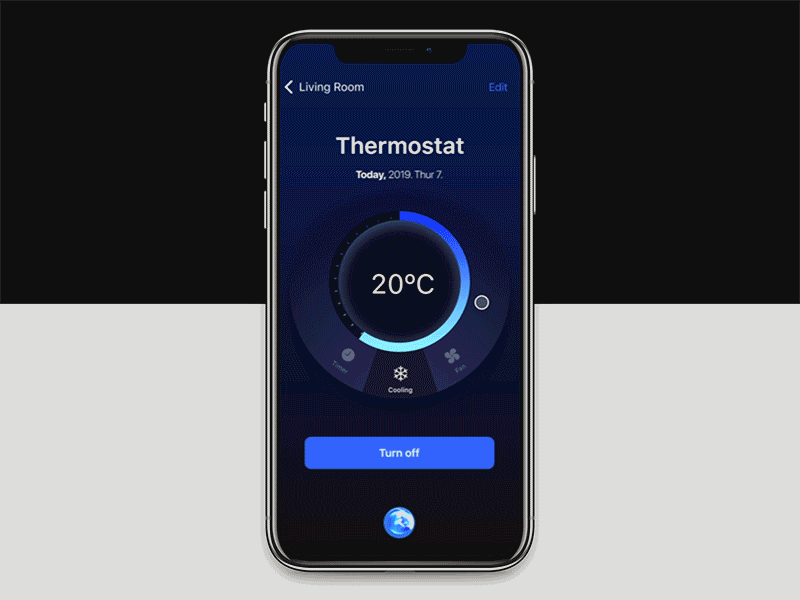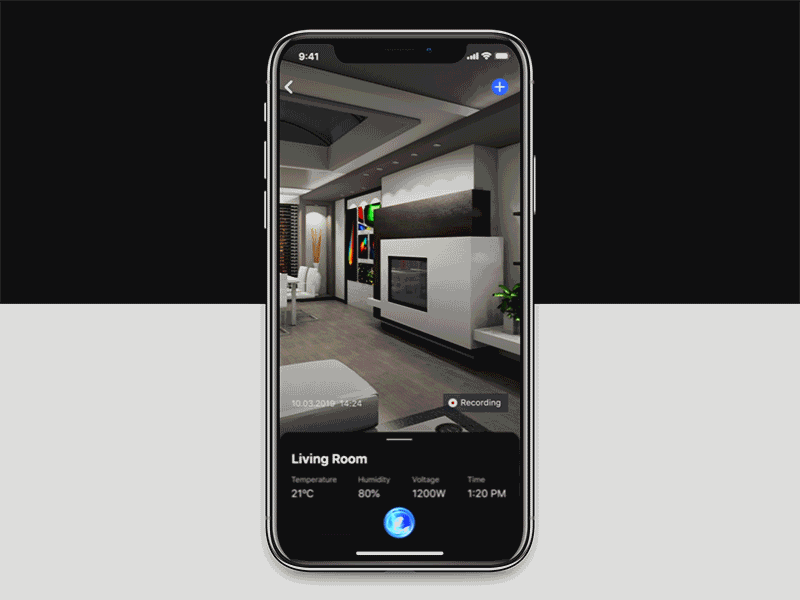
就日常工作而言–将手机连接至无线车载扬声器,我可以说“嗨,谷歌,早上好!” –这句话可以确保我在家的窗帘关闭,空调关闭,照明灯亮着变暗,可以让我了解路线上即将到来的交通情况,可以从我的日常日程中读出较大的内容,甚至可以通过启动“行车中的” Spotify播放列表来将所有内容排在首位。只要说四个字,我就能获得一整套完整的动作,并带来很大的愉悦感。
As far as daily routine goes – connecting my phone to my wireless car speaker allows me to say “Hey Google, good morning!” – a phrase that would make sure my curtains at home are shut, the air conditioner is off, the lights are dimmed, will update me on upcoming traffic in my route, read out loud items from my daily agenda – and maybe even will top it all with launching my “driving” Spotify playlist. By saying exactly 4 words, I get a complete suite of actions, with a large portion of delight.

预先基于语音或提供此类组件的产品数量正在上升。在表面刮擦时,我可以提到语音控制的飞利浦和小米灯泡,它们提供了各种情绪和情景。更引人注目的解决方案包括控制一系列设备的基于红外的RM-Pro设备,控制热水器和AC的产品,冰箱,自动吸尘器,眼罩,电源插座等-都是极限。
The sheer amount of products that are pre-based on voice, or offer such components, is on the rise. Scratching the surface, I can mention the Philips and Xiaomi lightbulbs that are voice controlled and offer a gallery of moods and scenarios. More notable solutions include the infrared-based RM-Pro device that controls an array of devices, products that control your water heater and AC, refrigerators, autonomic vacuums, blindfolds, power sockets and more – the sky’s the limit.

最重要的是,我们拥有控制应用程序(例如Google Home),可以通过创建仪式,同时无缝连接到助手来充当该乐队的指挥。这意味着我们的整个房屋都可以联机并根据要求进行控制,更重要的是–初始设置后,某些应用程序界面一旦“插入”到您的Assistant中就可以视为无关紧要。在可访问性方面,这些功能还帮助我们欢迎需要额外关注(例如视障人士)的未开发的新观众。因此,除了视觉界面及其好处外,VUI(语音用户界面)为我们所有人打开了新的交互可能性之门。
Above all these, we have control apps such as Google Home that act as conductors to this orchestra – by creating rituals, while being seamlessly connected to the Assistant. It means that our entire house can be online and controlled on request, and more importantly – after an initial setup, some of the applicative interfaces can be deemed irrelevant once “plugged” into your Assistant. In terms of accessibility, these capabilities also help us welcome new and untapped audiences that require the extra attention (such as the visually-impaired). So – alongside visual interfaces and their benefits, VUI (voice-user-interfaces) open the door to new interaction possibilities to us all.
如果这还不够,请花点时间看一下这个概念证明,最近它已成为现实:
If that’s not enough, invest a moment of your day and watch this proof of concept, which recently became a reality:
屏幕后和用户体验时代
The post-screen and user experience era
基于语音和语音的界面是各种感觉所构想的纯人机交互的示例。没有可视界面,屏幕接近零。进行了一个(很短的)入职过程,显然需要正确计划。我们希望普通用户能够操作该产品,并使用一个简单的应用程序将其连接到网络-从这一点开始,无需进一步考虑就可以与它进行交谈。
Voice and speech-based interfaces are examples of pure man-machine interaction, as conceived by various senses. There isn’t a visual interface, with near-zero screens. A (hopefully short) on-boarding process takes place, with an obvious need to plan it right. We expect the average user to be able to operate the product, to connect it to the web using a simple app – and from this point on start talking to it with no further thought.

作为用户体验设计师,我的目标是目标受众的直觉。我确信我们大多数人已经投入了时间和精力来计划,研究和实施从用户的行为中学到的外卖方法,所有这些目的都是为了能够以最方便和透明的方式完成中央行动。向前迈进:系统与用户进行对话的能力至关重要,请考虑产生直观参与的难易程度,此外,还要求您不要使用视觉辅助。
Being a UX planner, I aim for my target audience’s intuition. I’m sure that most of us already invest time and thought into planning, researching and implementing the takeaways learned from our users’ behavior, all with the intention to be able to accomplish the central action in the most convenient and transparent manner. Taking it a step forward: the ability of your system to have a conversation with your users is crucial, think about how difficult it is to generate intuitive engagement – and add to that the fact that you’re required not to use visual aids.

从我们作为界面和经验设计师的角度来看,我们看到了范式的转变。我们专注于屏幕,外观,微交互(所有这些仍然很重要)–现在我们要绘制一个新的图表世界,其中包括:对话树,直接端点,语气,数据源,对话主题,实时等等。
We see a paradigm shift, from our perspective as interface and experience designers. We had focused on screens, appearance, micro-interactions (all of these are still important) – now we have a new world to chart, that includes: conversation trees, immediate endpoints, tone of voice, data sources, conversation topics, analysis in real time and much more.

相信我,对此类事物进行定性的用户研究需要改变观点。我们必须考虑所有问题,从检查最简单的表达问题的最基本方式(以使其简短而准确地回答问题)到创建不太机器人化或令人毛骨悚然的体验。
Trust me, conducting a qualitative user research for such a thing requires a change of perspective. We have to consider everything from checking what’s the most basic way to phrase a question (in order for it to get a short and accurate response) and up to the creation of an experience that’s not too robotic or creepy
与平行区域的同事进行的对话确认,除了用户体验之外,还需要进行进一步的调整。内容必须清晰,重点突出,才能被认为是对口头问题的正确答案。我指的是会影响Google(和其他公司)扫描和解释文本能力的技术准备。如果正在进行市场营销工作,那么对他们来说,至关重要的是要与我们试图与之互动的新经验保持一致。这些不再只是算法,而是无缝连接到物理设备的虚拟系统,同时消除了对“官方应用程序”的需求。因此,UXer在包括(或基于)语音组件的产品开发阶段中的作用更加关键和重要。
Conversations with colleagues in parallel areas confirm that further adjustments are required, apart from user experience. The content must be clear and focused enough to be deemed a worthy answer to a spoken question. I’m referring to technical preparation that affects Google’s (and other companies’) ability to scan and interpret the text. In case there are marketing efforts taking place – it’s crucial for them to be in line with the new experience we’re trying to generate engagement with. Those are no longer just algorithms, but virtual systems that seamlessly connect to physical appliances, while negating the need for “official apps”. Therefore, the role of UXers in the development stage of products that include (or based on) voice components, is more crucial and central.
下次您说“嘿Google,给我讲个笑话”或“使绿松石变成浅绿色”或“在我打ze睡之前先数一下羊”(请:)),并得到适合所有人的清淡,有益或有用的答案,而不会冒犯任何人–请记住,有一些用户体验专家会花时间和精力来设计整件事。
Next time you say “Hey Google, tell me a joke” or “make the light turquoise” or “count sheep before I doze off” (please :)) – and get a light, informative or useful response that suits all and offend none – remember that there are user experience professionals that invest time and thought into engineering this entire thing.
调整自己
Adjusting ourselves
当您考虑设计语音接口时,我整理了几个主题供您参考。让我们看看人类之间的交谈方式,看看是否可以从中推断出语音界面的声音和感觉。
I had assembled several topics for you to refer to when you think about designing a voice interface. Let’s look at the way we humans talk with each other and see if can deduce from that how a voice interface should sound and feel.
1.引起注意,直觉和持续
1. Addressing attention, intuition and continuance
当我们与另一个人交谈时,我们实际上需要以上三个条件。这个过程需要我们谈话的人的注意,然后是关于响应可能如何的某种直觉,然后准备根据该响应继续对话。基于语音的系统应该受到这些方面的启发。
When we have a conversation with another person, we actually need all three of the above. The process requires attention from the person we are speaking to, followed by some kind of intuition as to how the response might be and then be prepared to continue a conversation based on that response. A speech based system should be inspired by those aspects.

一个成功的基于语音的系统的定义很大程度上取决于用户与之流畅交互的能力。口吃,误解或无关紧要将加深概念上的差距,并提醒该人基本的事实–他们正在与软件对话。为了使我们产生完美的幻觉,我们必须瞄准尽可能流畅的体验。当我们达到一个用户可以与产品进行完整对话的阶段时(几个句子,与单个查询相反),我们可以假定其他所有因素都可以解决。
The definition of a successful speech-based system largely depends on the user’s ability to interact smoothly with it. Stuttering, misunderstanding or irrelevance will deepen the conceptual gap and remind the person the fundamental truth – that they’re talking to a piece of software. In order for us to create the perfect illusion, we must aim for the most fluent experience possible. When we reach a stage in which the user is being able to have a complete conversation with the product (several sentences, in contrast to a single query), we can assume that every other factor checks out.

重要的是要记住,在解决人们的注意力范围时,交互应该比平时更加直观,以便使我们达到与本质上是算法的语言对话的程度。如果Turing测试检查了计算机对人类测试人员而言声音可靠的能力–我认为语音助手已经远远超过了这一点,直到线路模糊为止(有时,需要发出声音略似“机器状”,以避免产生不和谐感)。
It’s important to remember that when addressing people’s attention span, the interaction should be even more intuitive than usual, in order for us to reach a point where we have a verbal conversation with what’s essentially an algorithm. If the Turing test examines the ability of a computer to sound reliable to a human tester – in my opinion, the voice assistants are well past this point, up until the fact that the lines are fuzzy (sometimes, there’s a need to make the voice slightly “machine-like”, to avoid a dissonance).
2.场景树
2.Scenario trees
让我们看一下一个相对基本的过程–与朋友自己安排早午餐,包括所有影响。我们必须在空闲时间前后进行相互调整,以确认并在日历中做笔记(带有特定时间(用于提醒和放置)(用于可单击的导航))。可以很容易地看到这一系列动作如何使一个程序陷入困境,以及这个琐碎的动作需要多少个场景树。创建基于语音的界面的主要部分取决于创建详细方案树的需求。您可以通过使系统“学习”并自己生成新方案而获得奖励积分-这导致了流行的“机器学习”流行语。
Let’s take a look at a relatively basic process – scheduling a brunch with a friend, with all of the implications, by ourselves. We have to adjust to each other around our free time, to confirm, to make a note in the calendar (with the specific time – for a reminder, and place – for clickable navigation). It’s easy to see how this chain of actions could stump a program, and how many scenario trees this trivial action requires. A major part of creating voice-based interfaces is dictated by the need to create detailed scenario trees. You get bonus points for making your system “learn” and generate new scenarios by itself – which leads to the popular “machine learning” buzzword.

例如,当我与Google Assistant交谈时,我倾向于在语音交流结束时添加“谢谢”。对我来说,作为UXer,这可能意味着经验是成功的(并且已经得出了方案的结论)。当主要的用户输入是语音,并且用户添加了对系统表示感谢的“额外”提示时–这意味着已达到目标。短信和故事文化引导我们创建简短的内容并立即采取行动。从语言的角度来看,语音界面以完整清晰的句子甚至一点礼貌来“重新训练”我们的会话技巧,欢迎您自己尝试…
For example, when I speak with Google Assistant, I tend to add “thank you” at the end of our vocal exchange. For me, as a UXer, it can mean that the experience was successful (and the conclusion of the scenario had been reached). When the primary user input is voice, and a user adds the “extra” touch of thanking the system – this means that the goal was reached. The SMS and Story culture lead us to creating abbreviated content and immediate actions. In the perspective of language, voice interfaces “re-train” us in conversation skills, with complete and clear sentences, and even a bit of politeness You’re welcome to try it yourselves…
3.测量和用户研究
3.Measurements and user research
对于那些从事语音接口(或组件)开发的人员,我建议您尽早在产品生命周期内考虑进行定量的用户研究。在某些时候,您必须能够衡量系统的性能-这源于设置特定的KPI。
For those of you engaged in the development of voice interfaces (or components), I’d suggest thinking about quantitative user research, as early in the product’s life as possible. At some point, you’ll have to be able to measure the system’s performance – which originates in setting specific KPIs.
“显而易见”的指标是成功完成的动作的数量,但就我个人而言,我认为流畅的交谈也是成功的。含义:系统具有在相同上下文中进行包含多个动作的会话的能力,同时保留了收集大数据的能力,有利于改进算法。
The “obvious” metric is the number of actions that were accomplished successfully, but personally, I consider a fluent conversation also a success. Meaning: the system’s ability to have a session that includes more than one action within the same context, while retaining the ability to collect big-data, in favor of improving the algorithm.
在基于语音的系统研究领域,有两种通用方法:定性用户研究和定量数据。
In the field of voice-based system research, there are two general approaches: qualitative user research, and quantitative data.

让我们首先谈谈言语方面。定性的用户研究非常简单。最好的情况是与用户自己交谈,听普通的对话结构。最好的情况很少是对话的文字记录。此处的目的是确定过程何时成功完成,以及交换是否为正。
Let’s address the verbal aspect first. Qualitative user research is pretty much straightforward. Best case is speaking with the users themselves, listening to an average conversation structure. Slightly-less best case is a textual transcript of conversations. The purpose here is to identify when the process was completed successfully, and whether the exchange was positive or not.
定量研究不是那么简单。一般而言,在这种情况下,UX研究需要专有工具的初期开发,或者至少是大量定制现有工具。我们必须教一个系统“成功”和“失败”是什么,以识别过程中的痛点,甚至放弃。在没有数据的情况下,可能会出现该过程根本无法成功的状态,但就系统而言,确实是这样。系统可以根据您要求的巧克力曲奇配方找到您要的歌曲(对此结果有几种解释)。

Quantitative research is not that simple. Generally speaking, UX research in this context requires the initial development of proprietary tools, or at least heavily customizing existing tools. We have to teach a system what “success” and “failure” are, to identify pain points within the process, and even abandonment. In the absence of data, there could be a state in which the process wasn’t successful at all, but as far as the system sees it – it was. The system was able to find the song you asked for, in response to asking for a chocolate chip cookies recipe (there are several explanations for this outcome).
简而言之,期望遍历许多流程图
In short, expect to go over many, many flowcharts
“即将推出”部分
The “coming soon” part
如果能够体现出市场领导者的远见,我们将能够选择是否在不借助屏幕的情况下,通过云很快地进行自己的操作-连接了所有内容:日程安排,电器,智能汽车和符合我们所有需求的例程。用户体验架构师将这留在哪里?我们必须开始考虑是否应该在某个位置集成语音用户界面(或组件),并在该位置进行集成。当您能够在正确的时机提供正确的解决方案时–您将掌握杀手级功能。
If the vision of the market leaders will be manifested, we’ll be able to choose whether to conduct ourselves without screens, via cloud, very soon – with everything connected: schedules, electric appliances, smart cars and routines that tend to our every need. Where does this leave us, user experience architects? We must start to think if and where we should integrate a voice user interface (or component), assuming it serves the purpose. When you are able to offer the right solution at the right moment – you have a killer feature in your grasp.
亚马逊的Alexa通过不断增强自身兼容性,改进AI并为外部“技能”留出足够的空间来增强Alexa的知识和能力,从而不断扩展其生态系统。每个技能都是用户体验的缩影,包裹在相同而熟悉的声音中。
Amazon’s Alexa is constantly expanding its ecosystem, by making itself more compatible, by improving the AI and leaving enough space for external “skills” to enhance Alexa’s knowledge and abilities. Each skill is a microcosmos of user experiences, wrapped in the same, familiar voice.

如果上述所有操作都能完美执行,并且不需要上例中所述的“紧要”时刻进行修复,那么我们将拥有出色的使用经验,可以跨平台,在后台运行并进行量化和测量。最重要的是:如果所有这些都归结为满意的用户,他们获得了他们想要的东西,并且我们能够使他们免于更多的操作和更多的屏幕来查看–我们就是黄金。那就是我们所有人的目的,不是吗?
If all of the aforementioned is executed flawlessly and doesn’t require attendance and fixes in “crucial” moments like in the example above – we have an excellent usage experience, that crosses platforms, runs in the background and is subjected to quantification and measurement. On top of it all: if all of this sums up to happy users that got what they wanted, and we were able to spare them from more actions and more screens to look at – we’re gold. That’s what we’re all here for, isn’t it?
